AI, consciousness & Vedanta

In this post, I want to talk about 2 very interesting concepts of tree recursion & memoization, which I’ve been exploring in the wonderful book, SICP (here’s why). I’ve also tried to re-implement these concepts from the language Scheme, used in SICP, to Python, to reinforce my understanding of these concepts & also to explore functional programming paradigm in Python.
Before we dive in, here’s a very short primer on one of my favorite concepts in programming, recursion with Scheme.
One of the quintessential examples of a recursive procedure is the factorial function. Here’s the Lisp (Scheme) code from SICP to describe factorial, a function that calls itself recursively:
(define (factorial n)
(if (= n 1)
1
(* n (factorial (- n 1)))))
Recursive procedures for functions like factorial are often intuitive to write due to their similarity with the mathematical definitions. However, their performance is not always optimal (Consider the no. of delayed multiplications that keep getting added to the stack until we reach the base case). To overcome this challenge, we can re-write these procedures using state variables that describe each intermediate state completely, ie, using iteration. We can define such iterative processes using recursive procedures as well, by using tail recursion. Here’s the tail recursive (iterative) procudure for implementing factorial from SICP in Scheme:
(define (factorial n)
(define (helper product counter max-count)
(if (> counter max-count)
product
(helper (* counter product)
(+ counter 1)
max-count)))
(helper 1 1 n))
Compared to previous function definition of factorial, notice that in a tail recursive function, there are no pending multiplications like we saw earlier. One function call ends and the other one begins cleanly. There is no memory overhead for keeping track of multiple stacks of previous function calls. Tail recursion uses constant memory space compared to the growing (initially) & shrinking (later) memory space consumed by the original recursive procedure. This leads to better performance for tail recursive functions.
Alright, so now let’s focus on a special kind of recursive procedure, tree recursion, where each function call can spawn mutliple recursive function calls. The most classic example for this is the function to compute Fibanacci numbers. Here’s the Scheme code from SICP:
(define (fib_tree n)
(cond ((= n 0) 0)
((= n 1) 1)
(else (+ (fib_tree (- n 1))
(fib_tree (- n 2))))))
While this is a mathematically intuitive way to write the function, the function fib_tree calls itself twice each time it is invoked. The tree-recursive process generated while computing the 5th Fiboncci no is shown below (courtesy SICP):
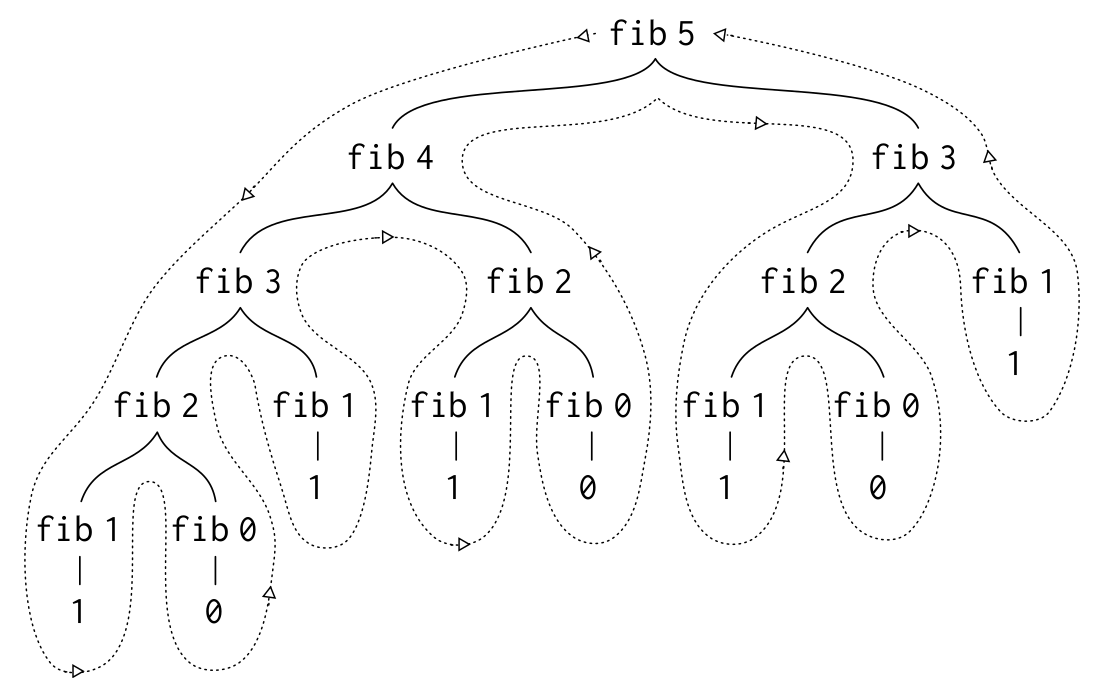
As we can see from the figure, we end up doing a lot of redundant computation to calculate (fib_tree 5). This process blows up exponentially with the input n. Below, I’ve implemented the same tree recursive procedure, fib_tree, in Python:
def fib_tree(n):
if n in [0,1]:
return n
else:
return (fib_tree(n-1) + fib_tree(n-2))
fib_tree(5)
5
Let’s see the time taken by this exponential process takes to compute the 40th Fibonacci no:
%%time
fib_tree(40)
CPU times: user 36.1 s, sys: 0 ns, total: 36.1 s
Wall time: 36.2 s
102334155
36 s! That’s clearly a terrible way to compute Fibonacci nos. We can improve the time complexity of this process if we use tail recursion instead.
Here’s the iterative (tail-recursive) solution from SICP:
(define (fib_iter n)
(define (helper a b count)
(if (= count 0)
b
(helper (+ a b) a (- count 1))))
(helper 1 0 n))
Notice, how we again define an internal helper function and state variables like we did for the iterative factorial procedure above. Next, I’ll convert the code into Python & see if we can improve the performance.
def fib_iter(n):
def helper(a, b, counter):
#print(f"Calling loop for counter = {counter}")
if counter == 0:
return b
else:
return helper(a+b, a, counter-1)
return helper(1, 0, n)
%%time
fib_iter(40)
CPU times: user 73 µs, sys: 2 µs, total: 75 µs
Wall time: 78.7 µs
102334155
78 x 10-6s vs 36 s! This is faster than the tree recursive procedure by 6 orders of magnitude !!
But we can see that designing a tail recursive procedure is not always the most intuitive solution. So, let’s look at another trade-off instead.
Notice the missing “r” :D Memoization is a programming idiom that can help improve the performance of recursive procedures by storing intermediate results into a cache (memo). So if we end up calling a function with some common values, duplicate function calls that we saw in the figure above can be avoided.
Writing memoization in a functional language like Scheme though looks awkward, as it veers away from “pure” functional programming by mutating the value of the cache:
(define fib_memo
(letrec
((memo null)
(f (lambda (x)
(let ((ans (assoc x memo)))
(if ans
(cdr ans)
(let ((new-ans
(if (or (= x 1)
(= x 2))
1
(+ (f (- x 1))
(f (- x 2))))))
(begin
(set! memo (cons (cons x new-ans) memo))
new-ans)))))))
f))
I’ve added the Python implementation below which admittedly looks much easier to read. I’ve made 1 important change though. Instead of the list data structure, I’m using the Python dictionary, an abstract data type that’s implemented as a hash table, and so should add some performance benefit in lookup. I’ve also initialized the dictionary (memo) for the nos 0 & 1, ie, the base cases.
def fib_memo(n):
memo = {0:0, 1:1}
def helper(x):
if x in memo:
return memo[x]
else:
memo[x] = helper(x-1) + helper(x-2)
return memo[x]
return helper(n)
Now, let’s get back to measuring the running time for calculating the 40th Fibonacci no:
%%time
fib_memo(40)
CPU times: user 24 µs, sys: 1 µs, total: 25 µs
Wall time: 27.7 µs
102334155
This is comparable to the tail recurisve procedure, slightly faster, but still 6 orders of magnitude faster than the tree recursive procedure !! That’s because once we compute Fibonacci(5) say and store it to our cache, the subsequent calls will access it’s value in near constant time from the Python dictionary.
Alright then, if you are one of those people that get excited about concepts like recursion, and want to explore functional programming more, I’d highly encourage you to read SICP. I’ve written another blog post on my experience with studying SICP here. If you’re more of a MOOC person, the Programming Languages course by Prof Dan Grossman on Coursera is really amazing, do check it out!
PS - If you want to play around with the Python code, you can go ahead and fork this Kaggle Kernel.
5 books to offer a different perspctive on life
Why do many companies still ask CS puzzle type questions in their coding round for DS roles
Looking at the design recipes for 2 common sorting algorithms in Scheme
Don’t teach yourself data science in 10 days, but in 10 years
Some valuable lessons I learnt in my recent job search experience
And why you don’t need another ‘How to become a data scientist in 2021’ listicle
An intuitive way to look at matrix vector multiplication, with applications in image processing
Most tech firm interviews include SQL problems for DS roles, so how should you prepare for them?
Implementing basic matrix algebra operations in Scheme using a Jupyter notebook
Building a gender classifier model based on the dialogues of characters in Hollywood movies
Simple EDA of my reading activity using tidyverse on R Markdown
My experience using productivity tools for personal projects
Comparing Tree Recursion & Tail Recursion in Scheme & Python
My notes halfway through the book Learn You A Haskell
My topsy turvy ride to data science
Books, MOOCs and other resources that I would highly recommend
The magic of SICP